
Current work on medical AI
Long-context inference. Training AI on longitudinal records quickly runs into computational challenges. In recent work, we show these problems can be avoided by bypassing language and more directly conveying concepts to language models.

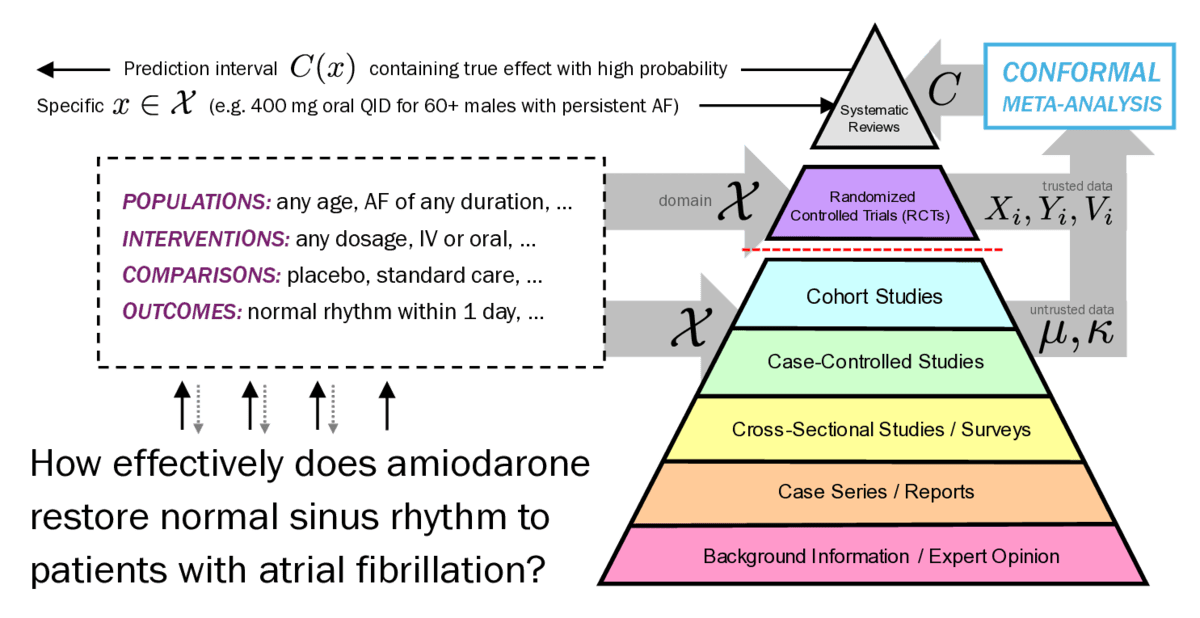
Unifying AI and EBM. A long-term goal is to create a system which answers questions about medical interventions in a rigorous, comprehensive manner. "Rigorous" requires meaningful, falsifiable guarantees about how well the causal effect is estimated. "Comprehensive" means using as much data as possible. Unfortunately, the two dominant paradigms for answering such questions — language models in artificial intelligence, and meta-analysis in medicine — don't have these properties. Language models don't enjoy correctness guarantees; meanwhile, to preserve their causal rigor, meta-analyses are restricted solely to randomized controlled trials. The solution is a careful fusion of these approaches which I call conformal meta-analysis.
Selected papers
- The Verbose Context Problem By Shiva Kaul, Kaan Kale, Min-Gyu Kim, Ahmet Ege Tanriverdi, Anjum Khurshid, and Sriram Vishwanath. Submitted.
- Position: Medical AI Neglects Real Treatment Outcomes By Shiva Kaul and Anjum Khurshid. Submitted.
- How Balanced Should Causal Covariates Be? By Shiva Kaul and Min-Gyu Kim. Submitted.
- Meta-Analysis with Untrusted Data By Shiva Kaul and Geoffrey J. Gordon. ML4H 2024. Full arXiv version
- Classical Improvements to Modern Machine Learning Ph.D. Thesis, CMU-CS-24-137
- Linear Dynamical Systems as a Core Computational Primitive By Shiva Kaul. NeurIPS 2020. Selected for Spotlight Presentation. Code
- Measuring the Sympathetic Response to Intense Exercise in a Practical Setting By Shiva Kaul, Anthony Falco, and Karianne Anthes. MLHC 2019
- Margins and Opportunity By Shiva Kaul. AAAI/AIES 2018. Selected for Doctoral Consortium
Selected talks
- What is Population Health AI? Dept. of Population Medicine, HPHCI / Harvard Medical School, October 2025
- Meta-Analysis with Untrusted Data Sunlab, University of Illinois, September 2024
- Classical Improvements to Modern Machine Learning Ph.D. Thesis Defense, August 2024. Full PPT
- Linear Dynamical Systems as a Core Computational Primitive NeurIPS 2020 Spotlight. Poster and Video
- Trusting Modern Machine Learning Allergan Scientific Series, January 2020
- Symmetric Tensor Rank SELECT LAB, Carnegie Mellon, Spring 2013
- Semidefinite Programming Hierarchies for Polynomial Programs 10-725 Optimization Lecture, Carnegie Mellon, Fall 2012
- Conic Duality 10-725 Optimization Recitation, Carnegie Mellon, Fall 2012
- Anticoncentration Regularizers for Stochastic Combinatorial Problems NIPS 2011 Workshop on Computational Trade-offs in Statistical Learning
- Electronic Structure Theory, Quickly SELECT LAB, Carnegie Mellon, January 2011
Open source
neopatient is an open-source software package for language-controlled generation of artificial patient records. Longitudinal patient records are useful for training and evaluating AI, but real ones are encumbered. Just write out (in natural language) what you do/do not want the patients to be like. neopatient handles sampling, chunking, batching, structuring, and verification. It cost-effectively generates lots (tens of thousands) of records, each up to 100K+ tokens, in the MEDS format.
Teaching
I was a teaching assistant for following courses at Carnegie Mellon:- 10-725 Optimization, a graduate-level course in optimization for machine learning researchers. Taught by Geoff Gordon and Ryan Tibshirani; assisted by myself, Wooyoung Lee, Aaditya Ramdas, and Kevin Waugh.
- 15-359 Probability and Computing, an undergraduate-level course in probability and stochastic processes. It was taught by Mor Harchol-Balter and Klaus Sutner.
- IDEA MATH: Playing Prediction Games, a volunteer course taught at a summer camp for talented high school students.
- 98-085 Ruby on Rails, a student-led, twice-offered undergraduate course on the (at the time) brand-new, highly-productive web application framework.
Personal
I have participated in distance running, CrossFit, and (these days) powerlifting / barbell training. I enjoy cooking and taking care of Arktos, my Samoyed dog.

Contact
Email is preferred.